Data Sets¶
Currently DeepOBS includes nine different data sets. Each data set inherits from the same base class with the following signature.
-
class
deepobs.pytorch.datasets.dataset.DataSet(batch_size)[source]¶ Base class for DeepOBS data sets.
Parameters: batch_size (int) -- The mini-batch size to use. -
_make_train_and_valid_dataloader()[source]¶ Creates a torch data loader for the training and validation data with batches of size batch_size.
-
_make_train_eval_dataloader()[source]¶ Creates a torch data loader for the training evaluation data with batches of size batch_size.
-
_make_test_dataloader()[source]¶ Creates a torch data loader for the test data with batches of size batch_size.
-
_pin_memory¶ Whether to pin memory for the dataloaders. Defaults to 'False' if 'cuda' is not the current device.
-
_num_workers¶ The number of workers used for the dataloaders. It's value is set to the global variable NUM_WORKERS.
-
_train_dataloader¶ A torch.utils.data.DataLoader instance that holds the training data.
-
_valid_dataloader¶ A torch.utils.data.DataLoader instance that holds the validation data.
-
_train_eval_dataloader¶ A torch.utils.data.DataLoader instance that holds the training evaluation data.
-
_test_dataloader¶ A torch.utils.data.DataLoader instance that holds the test data.
-
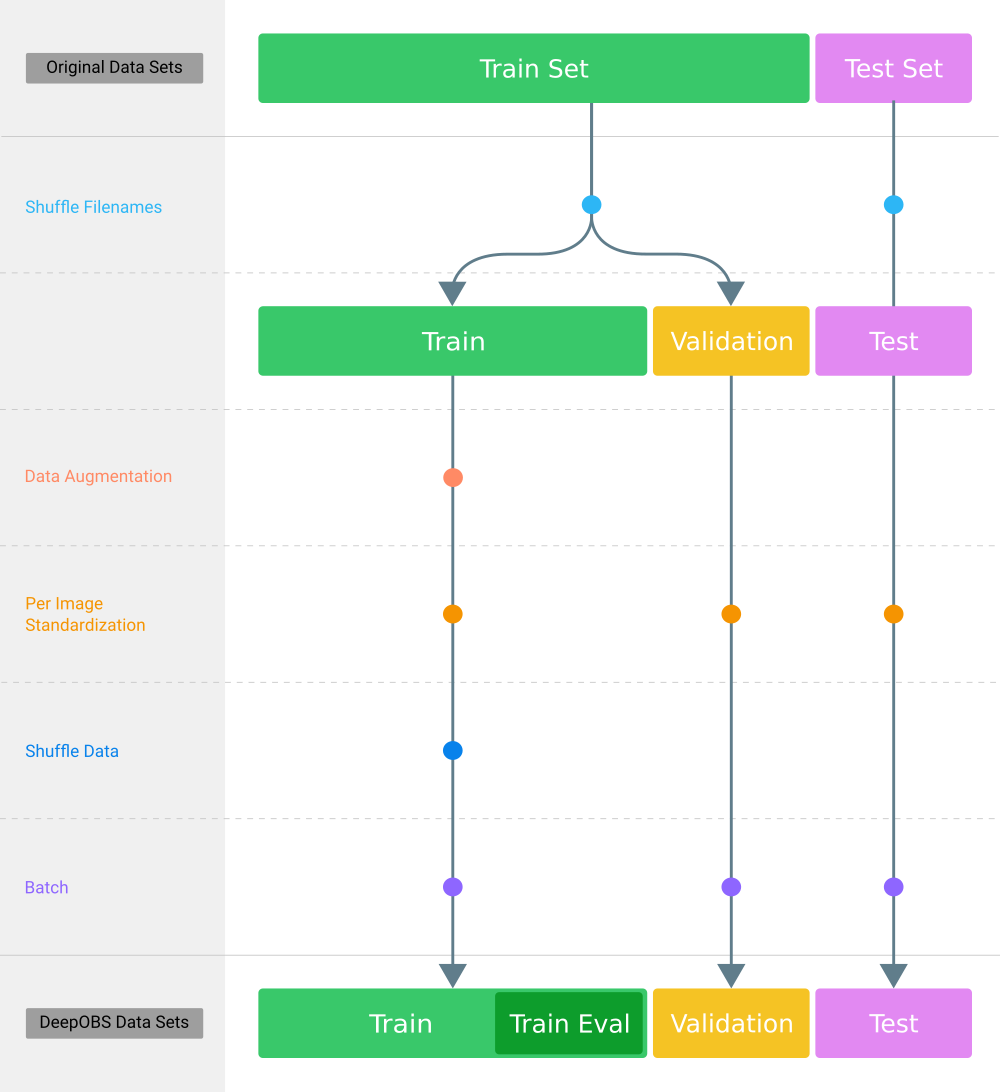
After selecting a data set (i.e. CIFAR-10, Fahion-MNIST, etc.) we define four internal PyTorch dataloaders (i.e. train, train_eval, valid and test). Those are splits of the original data set that are used for training, hyperparameter tuning and performance evaluation. These internal data sets (also called DeepOBS data sets) are created as shown in the illustration below.